Introducing Mobius: A Self-Improving AI System
A Researcher’s Worst Nightmare
This year, we set out to improve our consumer legal agent, which predicts the tasks a lawyer should take on a case. We imaginatively call this our Next Steps Agent.
Every time a prediction is made, the lawyers provide us with rich feedback. We had noticed that our lawyers were complaining about the same kinds of errors over and over again. So, we did what all good researchers do, and decided to look at the data.
The trouble is that Lawhive has 10,000’s of cases worth of data - many of these are closed, but the majority are in progress. The volume and unstructured nature of the data, coupled with the complexity of our systems, meant it would have taken (possibly) years for humans to identify the cause of the errors on their own.
Introducing Mobius
Large Language Models (LLMs) excel in tasks where the objective is clearly defined, and the data is messy, unpredictable, and vast. Lawhive stores ten times more data than Wikipedia[^1] (yes, really). So, we decided to build Mobius - an agentic system that finds opportunities to improve our systems, proposes fixes, and learns from its successes and failures over time.
The benefit of Mobius is that we can handle enormous quantities of feedback data. It’s usable anywhere we have lots of traces, a clearly defined measure of success, and a codebase.
The basic principle is that whenever we receive negative feedback from the lawyer on a prediction, we feed Mobius the production code, prompts, and traces (all the tools and data used by the Next Steps Agent to predict tasks). Using this information, Mobius examines the trace that led to the negative output, diagnoses the error modes, and proposes improvements to the Next Steps Agent. These Mobius “artifacts” are sorted in its “Memory Bank”, which enables Mobius to compound its knowledge over time.
Each proposal is reviewed by our research team as a testable hypothesis. We perform a sense check and either accept or reject the proposal; accepted proposals are then shipped to production. We closely monitor the next round of lawyer feedback and feed the result - accepted or rejected, improved or not - back into the Memory Bank. This ensures our development is iterative (delivering instant value to the user) and hypothesis-driven so that we (and Mobius) learn what constitutes an effective diagnosis and proposal.

How Mobius Improves Our Next Steps Agent.
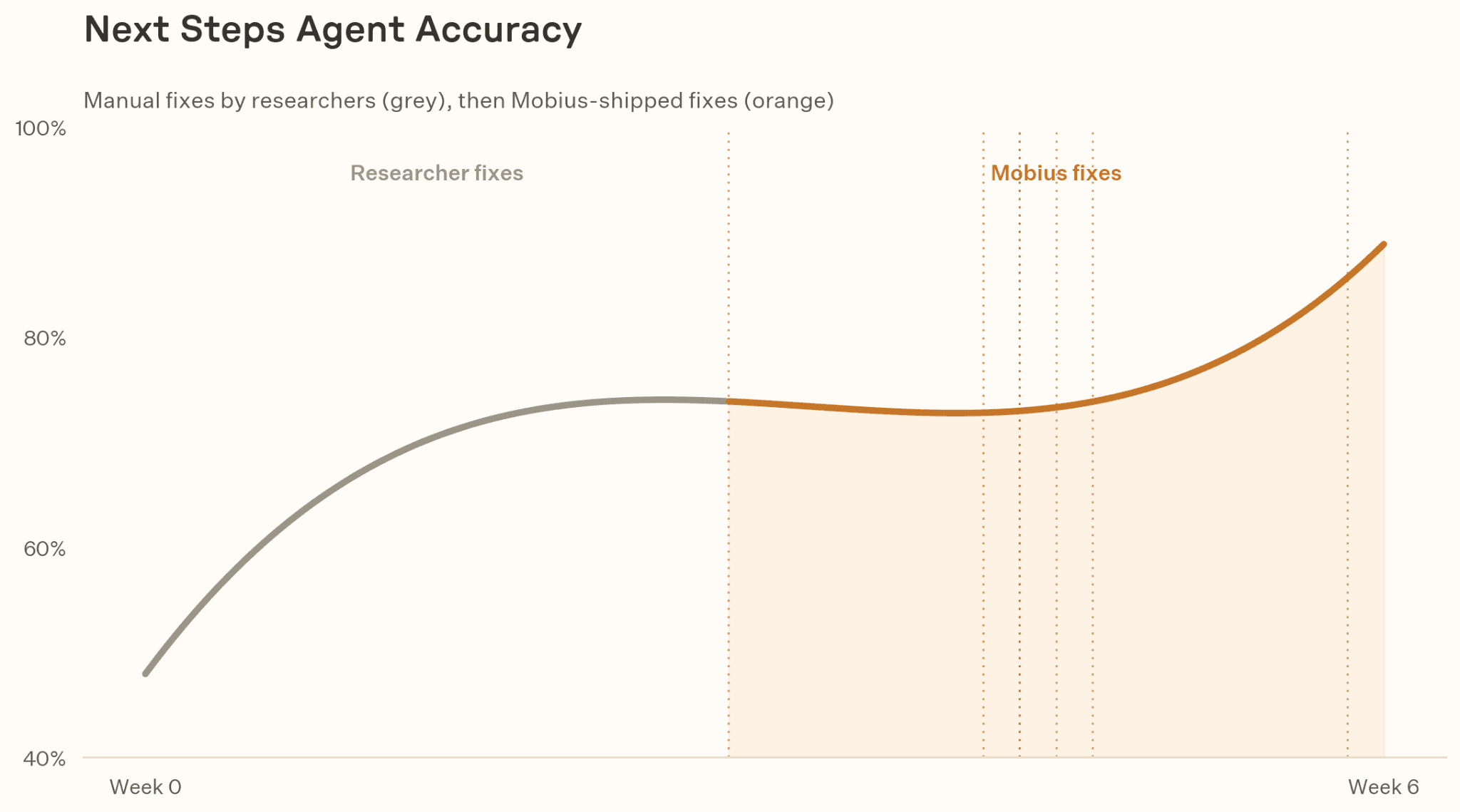
Within just six weeks, the accuracy[^2] of the Next Steps Agent had increased from 48% to 86%. Mobius’s proposals accounted for over half (56%) of the improvement (manual investigations by researchers accounted for the rest) and reduced the time taken from error detection to deployment to just two days. In total, seven of Mobius’s proposals were accepted.
With accuracy now over 90%, Lawrence can start to proactively complete the next steps on cases, empowering lawyers to provide a higher-quality, more responsive service to our clients. Here are some comments from our lawyers:
To be honest, it has been very helpful, especially with very critical suggestions that may be easy to miss.
The suggestions are good as they reveal that a proper scrutiny of correspondences and documents on the platform has been well evaluated..
Where do we go from here?
We’re going to use Mobius to improve all our other Agents, starting with the most used feature: chat. Before, Mobius improved an agentic system, but didn’t improve how it suggested those improvements. In other words, the instructions given to Mobius were fixed. This time, Mobius will be self-evolving, so that it learns not only to improve our Chat Agent but also to improve itself.
In time, Mobius will get better at getting better.
Acknowledgements
Thanks to Martin Hartt and Gareth Molyneux, who built and shipped most of the production-side fixes; Harry Green and Peter Zachares for pressure-testing the early research; Mostafa Yassin and Adolfo Tamayo for their work on our platform throughout the trial; Emtenan Suleiman for lending her professional legal experience and Tom Walkington for his enduring support for visionary research. Last but not least, a big thank you to the 15 in-house lawyers who spent six weeks providing us with consistent, specific feedback. They are the reason we’re able to continue delivering an affordable, excellent legal service to our customers.
[^1]: A conservative estimate of 60 billion tokens based on 30,000 cases, each containing a median of 2 million tokens worth of data. This is compared to 6 billion worth of tokens contained in Wikipedia https://en.wikipedia.org/wiki/Wikipedia:Size_of_Wikipedia
[^2]: We define accuracy as the percentage of predictions that have been given a thumbs up from our lawyers.